Graph-SQL
A graph consists of nodes (vertices) and edges (links). Nodes are the entities, such as a person (person) or a car (car). Edges connect nodes to each other. There are two types of edges in the example below: friends and owner.
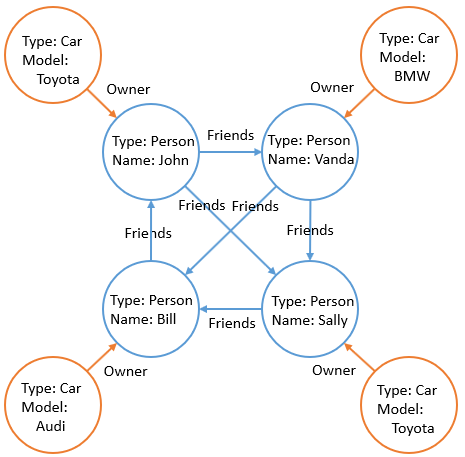
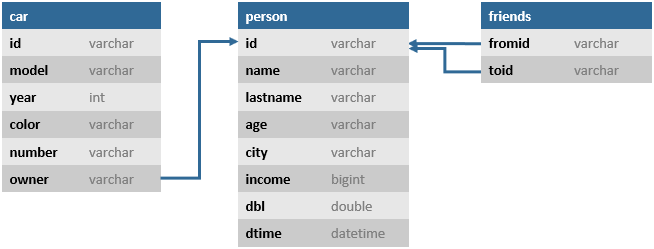
Nodes and edges (links) are stored in the tables. The "owner" relationship is presented as a simple Foreign Key field (many-to-one relationship). The "friends" many-to-many relationship is presented as a table of a special type EDGE(See «Demo Database»).
Presentation of a graph as the relational tables
Queries
MATCH
Graph-SQL is a language for running graph queries. It is a simple extension of SQL. Graph-SQL adds a new MATCH expression.
Let's start with a simple example. We want to find all people who have a car and who have friends having a car of the same model.
SELECT p1.name, p2.name as friendname, c1.model
MATCH (car c1)-[owner]->(person p1)-[friends]->(person p2)<-[owner]-(car c2)
WHERE c1.model = c2.model
MATCH expression is a pattern describing what objects and relationships we need to perform the query. MATCH replaces the FROM clause in SQL queries. The remaining clauses: SELECT, WHERE, ORDER BY, GROUP BY, HAVING, INTO are regular SQL expressions.
In the example below the MATCH expression describes:
- there is a node c1 of type car
- c1 by the link owner refers to the node p1 of type person
- p1 by the link friends refers to the node p2 of type person
- c2 by the link owner refers to the node p2
WHERE expression adds the condition c1.model = c2.model
The picture below shows a subgraph satisfying this query:
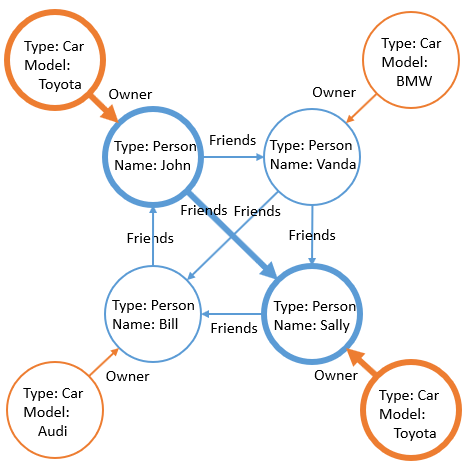
The query result looks like a regular SQL SELECT query result.
| name | friendname | model |
|---|---|---|
| John | Sally | Toyota |
Simple experssion MATCH presents a chain of the nodes and links. But what to do if the pattern cannot be represented as a chain? For example, we need to specify several links (more than two) from the node p1. In this case, we can add another MATCH expression.
SELECT p1.name, p2.name as friendname, c1.model
MATCH (car c1)-[owner]->(person p1)-[friends]->(person p2)<-[owner]-(car c2)
MATCH (p1)-[friends]->(person p3)<-[owner]-(car c3)
WHERE c1.model = c2.model and c3.model = c1.model
Please note that the second MATCH does not specify the p1 type since it has already been described earlier.
For your convenience, instead of a set of MATCH expressions (as in the example above), you can specify all the patterns under one MATCH expression separating them by commas (as in the example below).
SELECT p1.name, p2.name as friendname, c1.model
MATCH (car c1)-[owner]->(person p1)-[friends]->(person p2)<-[owner]-(car c2),
(p1)-[friends]->(person p3)<-[owner]-(car c3)
WHERE c1.model = c2.model and c3.model = c1.model
When searching for friends, you may need to limit the search depth (friends, friends of friends, friends of friends of friends, etc.).
The arrow -[friends]-> in the MATCH expression, representing a link, may contain the additional parameters for represintation of depth.
| expression | comment |
|---|---|
| -[friends]-> | depth equals 1 (friends) |
| -[friends 2]-> | depth equals 2 (friends of friends) |
| -[friends 3]-> | depth equals 3 (friends of friends of friends) |
An additional depth parameter can indicate that you need all intermediate nodes that are reachable by the link from one depth to another:
| expression | comment |
|---|---|
| -[friends 2,3]-> | depth range from 2 to 3 (friends of friends + friends of friends of friends) |
| -[friends 2,*]-> | depth is 2 and higher (friends of friends + friends of friends of friends + ...) |
| -[friends *]-> | the same as -[friends 1,*]-> |
Find all friends for John (as well as friends of friends and friends of friends of friends) living in the same city with him.
SELECT p1.name, p2.name as friendname
MATCH (person p1)-[friends 1..3]->(person p2)
WHERE p1.name = 'John' and p1.city = p2.city
MATCH! (exact order of execution)
MATCH! expression is similar to MATCH, but defines a strict order of navigation along graph nodes and edgrs.
Consider a query: get all the people 20 years old having a Toyota car
SELECT p1.id
MATCH! (person p1, p1.age=20)<-[owner]-(car c1, c1.model='Toyota')
The query starts with search of all 20-year old people. Further, for each found person all his cars are taken via [owner] link. And then for each found car the comparison is made: c1.model='Toyota'
When searching for people, an index on the age field can be used. If the search condition is more complex, multiple indexes or composite indexes can be used (see document SQL).
MATCH! allows you to optimize the execution a querу based on knowledge of subject area. In this particular case, we might know that there are few 20-year-olds in our database. And can cut off link transitions at an early stage, that considerably simplifies the query execution.
For example, we want to get friends of a certain person's friends, such that friends and friends of friends live with that person in the same city. A bad approach would be: we take a friend living in another city, then take his friends and only at the end we will check the conditions.
The query will work much faster if we immediately check each friend, and if he lives in another city, then we will not further check his friends.
SELECT p1.id
MATCH! (person p1, p1.id = 'person1')-[friends]->(person p2, p2.city = p1.city)-[friends]->(person p3, p3.city = p1.city)
In addition to simple SQL conditions, the MATCH expression can contain a distinct clause
SELECT p1.id
MATCH! (person p1, p1.id = 'person1')-[friends]->(person p2, p2.city = p1.city)-[friends]->(person p3, distinct, p3.city = p1.city)
In this case, distinct means that we want to get only unique p3 records. This distinct clause differs from classical SQL and serves to mark the nodes of the graph that we have already gone through. Therefore, use the distinct clause with caution.
For example, we want to get all the friends of a person's friends who have a car of the same make. The following 2 queries will return different results:
SELECT distinct p2.id
MATCH! (person p1, p1.id='person1')<-[owner]-(car car1),
(p1)-[friends]->(person px)
-[friends]->(person p2, p1.id != p2.id )
<-[owner]-(car car2, car1.model=car2.model);
SELECT p2.id
MATCH! (person p1, p1.id='person1')<-[owner]-(car car1),
(p1)-[friends]->(person px)
-[friends]->(person p2, distinct, p1.id != p2.id )
<-[owner]-(car car2, car1.model=car2.model);
The first query uses classical SQL distinct. The second query is wrong!
Suppose person1 has two cars: Toyota and VW. We take the first car of person1, then find a friend of his friend who has a VW car. The condition car1.model = car2.model will not work, but we have already marked the node of the graph corresponding to this person. Then, when we go back to person1 and now take VW, after that we take the same friend of a friend, we find that we have already been in this node and falsely discard it (although he also has a VW).
Graph data modification
Creaing graph structure
Data Definition Language (DDL) - basic graph expressions
| Query | Comment |
|---|---|
| CREATE TABLE DROP TABLE | Creating, deleting tables. Tables for graph edges are created with the extension AS EDGE. |
| ALTER TABLE | Table schema modification (adding, deleting the columns etc.). |
| CREATE INDEX DROP INDEX | Creating, deleting indexes. |
| You can also create an index to describe the many-to-one relationship for one or more fields (to create a foreign key relationship but without a constrain declaration) |
Data adding and deleting
Data Manipulation Language (DML)
| Query | Comment |
|---|---|
| INSERT INSERT INTO SELECT INTO BULK INSERT | Adding nodes and edges to graph is similar to adding records to relational tables. |
| DELETE | Deleting nodes and edges from the graph. |
| UPDATE | Modification of the values for individual columns of records. |
← SQL Native C/C++ API →